Get Ready for new excited event from AWS Summit 2023 ASEAN. Register: https://go.aws/45uCdyi
Implementing Observability using AWS Distro for OpenTelemetry (ADOT) will present:
– Introduction Observability and Monitoring – Introduction OpenTelemetry and ADOT (AWS Distro for Open Telemetry) – Demo sample with Golang RESTful API
In conclusion, by implementing AWS Distro for OpenTelemetry (ADOT), you have taken a crucial step towards ensuring the performance, reliability, and security of your RESTful API application.
With it’s powerful features and seamless integration with OpenTelemetry, ADOT provides real-time visibility into your API, helping you to quickly identify and resolve performance issues and keep your API running smoothly.
All material presentation will also publish in series at my personal blogs: https://devopscorner.id, stay tune and keep in touch!
Docker adalah sistem operasi untuk kontainer. Mirip dengan cara mesin virtual memvirtualisasi (menghilangkan kebutuhan untuk secara langsung mengelola) perangkat keras server, kontainer memvirtualisasi sistem operasi server. Docker memberikan perintah sederhana yang dapat Anda gunakan untuk membuat, memulai, atau menghentikan kontainer.
Penasaran gak sih gimana caranya menggunakan Docker untuk aplikas kamu?
Tenang aja sesi kali ini Dwi Fahni Denni, AWS Community Builder – Infrastructure & Cloud Services Manager Xapiens dan Muhammad Syukur Abadi, Student & Developer at Ngalam Backend bakal ngenalin docker dari awal banget nih.
As an integral part of the DevOps culture, Cost Monitoring & Optimization is the most important element in monitoring and optimizing the use of infrastructure, especially in today’s cloud computing era. In this event, we will discuss the strategy of cost monitoring & optimization of infrastructure in using Kubernetes (EKS) on AWS.
In this session, we will discuss provisioning estimation costs, autoscaling systems, downscale schedules, and alerting systems for cost usage notifications from cost limitation budgets.
Don’t miss ZX Talk – Infrastructure Kubernetes (EKS) Cost Monitoring & Optimization which will be held on:
Date: Thursday, 23 June 2022 Time: 14.00 – 15.30 (2 – 3.30 pm) Jakarta Place: Virtual Meet
In this article, I’d like to share about GitOps (Git Operations) and AWS Developer Tools to provide GitOps workflow.
I will separate our discussion with 3 section articles. This article will focus on GitOps and AWS Developer Tools, later on for 2 section articles in the future will discuss about The IaC (Infrastructure-as-Code) Tools using Terraform and The Implementation of IaC tools for provisioning infrastructure and it’s integration with AWS Developer Tools.
So, let’s go…
As Introduction, I will let you know about:
Introduction of GitOps
GitOps Pipeline
GitOps Workflows in DevSecOps
Introduction of GitOps
The introduction of GitOps (Git Operations) is starting from the term, if we take a look for the terms it self, there was a huge number of definition around the internet. In my opinion, the “GitOps” (Git Operations) is a way to do collaboration -as a team-, provide the operations of DevOps in releasing application, including version control, ci/cd and provisioning in modern cloud infrastructure.
Why we need GitOps?
Nowadays, thousands of delivering application took place in mobile platform. There was also numerous complexity of the application running background in web application. This application whether it’s running Web only or even in Mobile, had been built in more than a single programming language and more than a single layer of infrastructure architecture.
The more complex from the application, it will take more complex also in development & deployment process. In the GitOps workflow, collaboration team to work in sequence process is a part of DevOps culture, starting from versioning control of the source code, pull request (PR), pairing view code, approval process, delivering source code until testing in deployment environment.
This collaboration team also needed as a pair team to reproduce the steps or even to mitigate the errors that will come in the future.
GitOps Pipeline
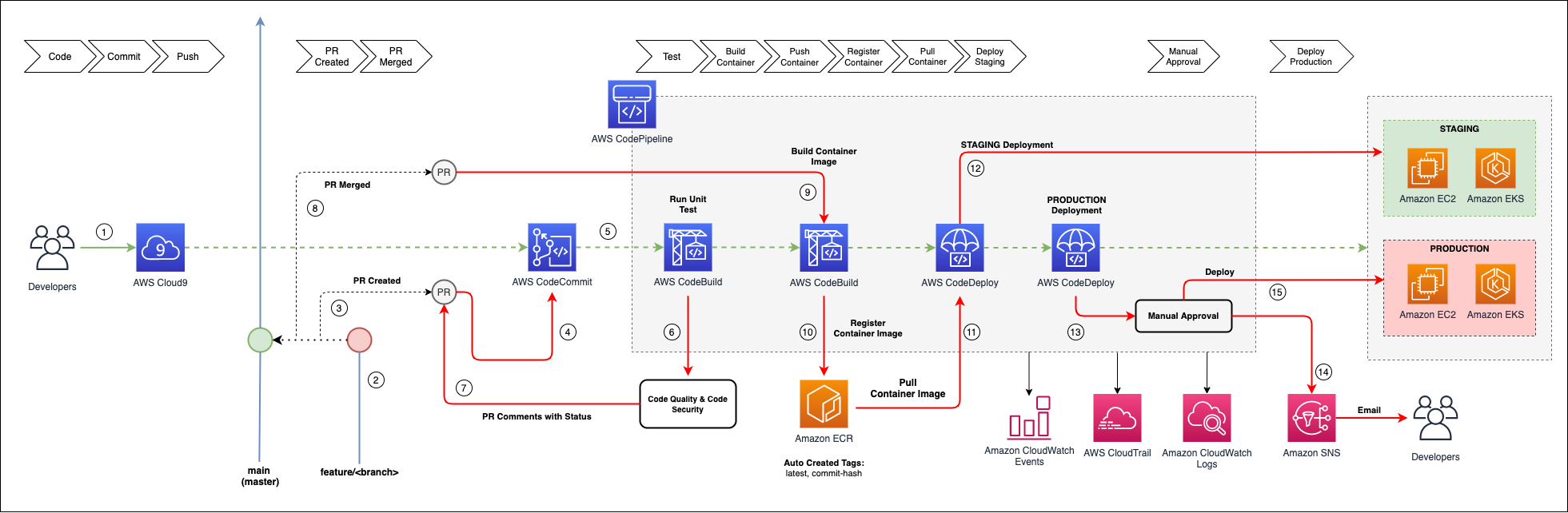
Diagram-1: GitOps Flow(enlarge for detail)
When we look at the ideal process of delivering a service from source code to provisioning the environment, there are a number of stages and processes involved.
In this Diagram-1 for example, you can see how the GitOps pipeline works in a deployment container application. The developers carry out development inside an isolated environment using AWS Cloud9 as an IDE, and they use AWS Developer tools to run build, test and deploy the services in the GitOps flow.
At the beginning, source codes will be pushed into AWS CodeCommit to make a PR (Pull Requests) step, this will also trigger AWS CodeBuild services to run inspection code for the code quality & code security check. If the PR is approved, it will run the pipeline to build the container image that will be registered inside Amazon ECR as a container registry.
The building image will be identified with tagging or commit hash that will also be pulled by AWS CodeBuild as references and delivered to the staging environment. Meanwhile for the production environment, approval will be needed before deployment process.
GitOps Workflows in DevSecOps
If we integrate the security pipeline (as shown in Diagram-2), it will have 2 additional stages – SAST & DAST. The Static Application Security Testing (SAST) including Security Configuration Assessment (SCA) will run before the deployment of the staging environment. The Dynamic Application Security Testing (DAST) will inspect and test the staging environment deployment before it is moved to the production environment.
Diagram-2: GitOps Workflow in DevSecOps(enlarge for detail)
This DAST will use a standard application that comes from OWASP(The Open Web Application Security Project).
How to Choose The Best Pipeline?
Again, my answer is depend, in how complexity your application layer and what kind of infrastructure do you plan to deploy.
In my opinion, if you need to deploy a static application that doesn’t need a complex database and integration, i will choose in the first diagram. But if the application layer will took place some of integration, such as 3rd party authorization, caching the assets (javascript, css, etc), session token, etc i will choose the second diagram as an ideal approach.
So, I hope this article bring you the knowledge about The GitOps and their workflow. We will see you again in other article for implementation GitOps flow with IaC Tools.
By default, API Gateway limits the steady-state requests per second (rps) across all APIs within an AWS account, per Region. It also limits the burst (that is, the maximum bucket size) across all APIs within an AWS account, per Region. In API Gateway, the burst limit corresponds to the maximum number of concurrent request submissions that API Gateway can fulfill at any moment without returning 429 Too Many Requests error responses. For more information on throttling quotas, see Amazon API Gateway quotas and important notes.
To help understand these throttling limits, here are a few examples, given a burst limit of 5,000 and an account-level rate limit of 10,000 requests per second in the Region:
If a caller submits 10,000 requests in a one-second period evenly (for example, 10 requests every millisecond), API Gateway processes all requests without dropping any.
If the caller sends 10,000 requests in the first millisecond, API Gateway serves 5,000 of those requests and throttles the rest in the one-second period.
If the caller submits 5,000 requests in the first millisecond and then evenly spreads another 5,000 requests through the remaining 999 milliseconds (for example, about 5 requests every millisecond), API Gateway processes all 10,000 requests in the one-second period without returning 429 Too Many Requests error responses.
If the caller submits 5,000 requests in the first millisecond and waits until the 101st millisecond to submit another 5,000 requests, API Gateway processes 6,000 requests and throttles the rest in the one-second period. This is because at the rate of 10,000 rps, API Gateway has served 1,000 requests after the first 100 milliseconds and thus emptied the bucket by the same amount. Of the next spike of 5,000 requests, 1,000 fill the bucket and are queued to be processed. The other 4,000 exceed the bucket capacity and are discarded.
If the caller submits 5,000 requests in the first millisecond, submits 1,000 requests at the 101st millisecond, and then evenly spreads another 4,000 requests through the remaining 899 milliseconds, API Gateway processes all 10,000 requests in the one-second period without throttling.
All of the API endpoints are rate limited. Once you exceed a certain number of requests in a specific period, Datadog returns an error.
If you are rate limited, you will see a 429 in the response code. Datadog recommends to either wait the time designated by the X-RateLimit-Limit before making calls again, or you should switch to making calls at a frequency slightly longer than the X-RateLimit-Limit / X-RateLimit-Period.
Datadog does not rate limit on data point/metric submission (see metrics section for more info on how the metric submission rate is handled). Limits encounter is dependent on the quantity of custom metrics based on your agreement.
The rate limit for metric retrieval is 100 per hour per organization.
The rate limit for event submission is 500,000 events per hour per organization.
The rate limit for event aggregation is 1000 per aggregate per day per organization. An aggregate is a group of similar events.
The rate limit for the Query a Timeseries API call is 1600 per hour per organization. This can be extended on demand.
The rate limit for the Log Query API call is 300 per hour per organization. This can be extended on demand.
The rate limit for the Graph a Snapshot API call is 60 per hour per organization. This can be extended on demand.
The rate limit for the Log Configuration API is 6000 per minute per organization. This can be extended on demand.
Rate Limit Headers
Description
X-RateLimit-Limit
number of requests allowed in a time period.
X-RateLimit-Period
length of time in seconds for resets (calendar aligned).
X-RateLimit-Remaining
number of allowed requests left in the current time period.
This is sample postmortem reporting to review chronologies, provide the mitigation from the issue and solving the problem during period time
Title
YYYY-MM-DD Issue Name. eg: 2020-09-01 Failed to Replicate Database Slave in Node-2.
Issue Summary
Summary of issue that describe all chronologies. eg: We had issue in replication slave server database in node-2. This issue running at 07:00 due to can’t connect the slave server DNS to DNS server master. Impacted to unable connected for some of microservices that using slave server as pointing reading / query read to database.
List of microservices impacted:
Microservices 1: Auth
Microservices 2: OTP
Impact
List of microservices or other infrastructure resources impacted for this issue. eg: Impacted microservices:
Microservices 1: Auth
Microservices 2: OTP
Impacted infra: DNS slave
Trigger
List of trigger issue. eg:
Cloud provider running on maintenance starting at 2020-09-01 02:00 GMT+7 and end at 2020-09-01 03:00.
Some of DNS changed as the impacted of maintenance.
Detection
List of detection issue. eg:
Detect on Metrics for failed replication (with snapshot picture)
Detect on Log for dns changes (with snapshot picture)
Root Cause
List of root cause for the issue. eg:
Slave server database in node-2 can’t running due to can’t connect to DNS server master.
DNS server master had been moved to other pointing address due to cloud provider maintenance.
Timeline
List timeline issue from beginning until end (resolved). eg: 2020-09-01 07:00 Metrics show failed to replicate the slave server database in node-2 2020-09-01 07:10 Raise the alert on P3 Escalation 2020-09-01 07:12 Oncall ack the issue 2020-09-01 07:15 Taking action for manual replication slave server 2020-09-01 07:30 All Replication had been restored 2020-09-01 07:35 Monitoring phase replication (for about 10-15 minutes) 2020-09-01 08:00 Operation slave server database in node-2 is back to normal
Resolution & Recovery
List of resolution & recovery action eg:
Manual replication for slave server
Repointing DNS slave node-2 to new DNS master
Corrective and Preventive Measurements
List of action item / procedure to make correction & prevention (as mitigation) eg:
Update threshold metrics for alerting, raise to P2 for escalation level.
Raise open ticket for cloud provider dns issue moving impact.
Financial Impact
Product Impacted
Start DateTime – End DateTime
Impact Type (Outage, Error Rates, Latency Spike)
Monitoring Links
Log Links
Detail of Financial Impact
Division / Team Name
List of division / team which impacted for this postmortem
Related Documents
Related documentation for this issue (JIRA / Confluences)










![[RFC] Rate Limits API Requests](https://devopscorner.id/wp-content/uploads/2022/02/devops-green-big-bg.jpg?w=825&h=510&crop=1)

You must be logged in to post a comment.