In today’s digital ecosystem, the complexity and scale of systems have reached unprecedented levels, presenting immense challenges in ensuring observability and maintaining optimal performance. Generative AI, a cutting-edge technology, is revolutionizing the landscape of observability by offering innovative solutions to these challenges.
This presentation explores the transformative power of Generative AI in enhancing observability across various domains. By leveraging advanced machine learning algorithms, Generative AI enables the creation of synthetic data that closely mimics real-world scenarios, facilitating comprehensive testing and analysis in controlled environments.
Furthermore, Generative AI empowers anomaly detection and predictive analytics by generating synthetic data patterns that represent potential system failures or irregularities. This proactive approach enables organizations to identify and address issues before they escalate, thus minimizing downtime and optimizing performance.
Moreover, Generative AI fosters the development of adaptive monitoring systems capable of learning from dynamic environments and evolving threats. By continuously generating and analyzing synthetic data, these systems adapt in real-time, ensuring robust observability even in the face of rapidly changing conditions.
Through case studies and practical examples, this presentation demonstrates how Generative AI is reshaping the observability landscape, offering unparalleled insights, and driving innovation across industries. From IT infrastructure to cybersecurity and beyond, Generative AI is revolutionizing how we monitor, analyze, and optimize complex systems in the digital age. Join us as we explore the limitless potential of Generative AI in transforming observability and unlocking new frontiers of performance and reliability.
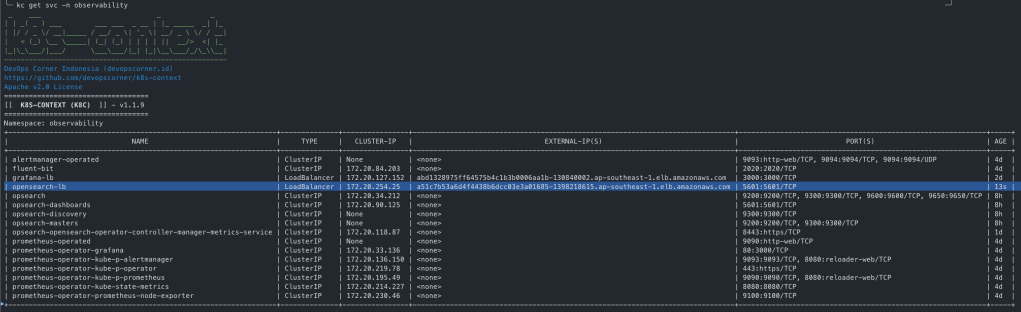
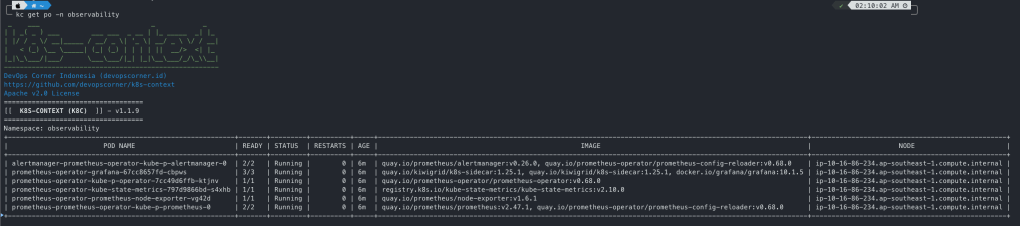
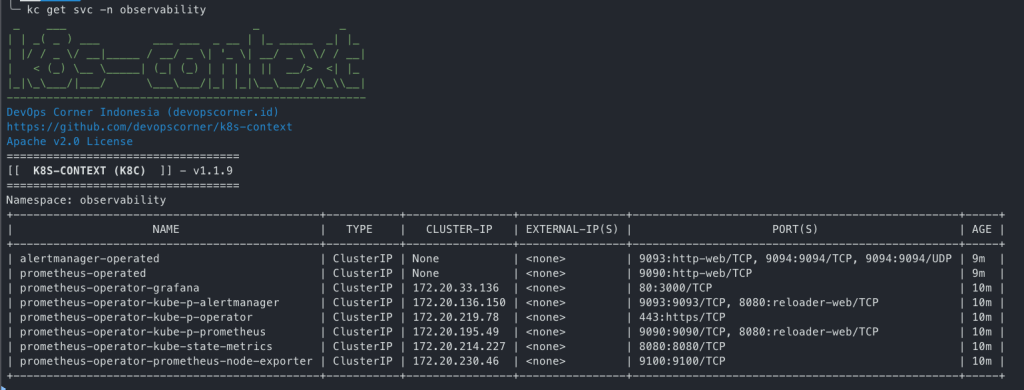
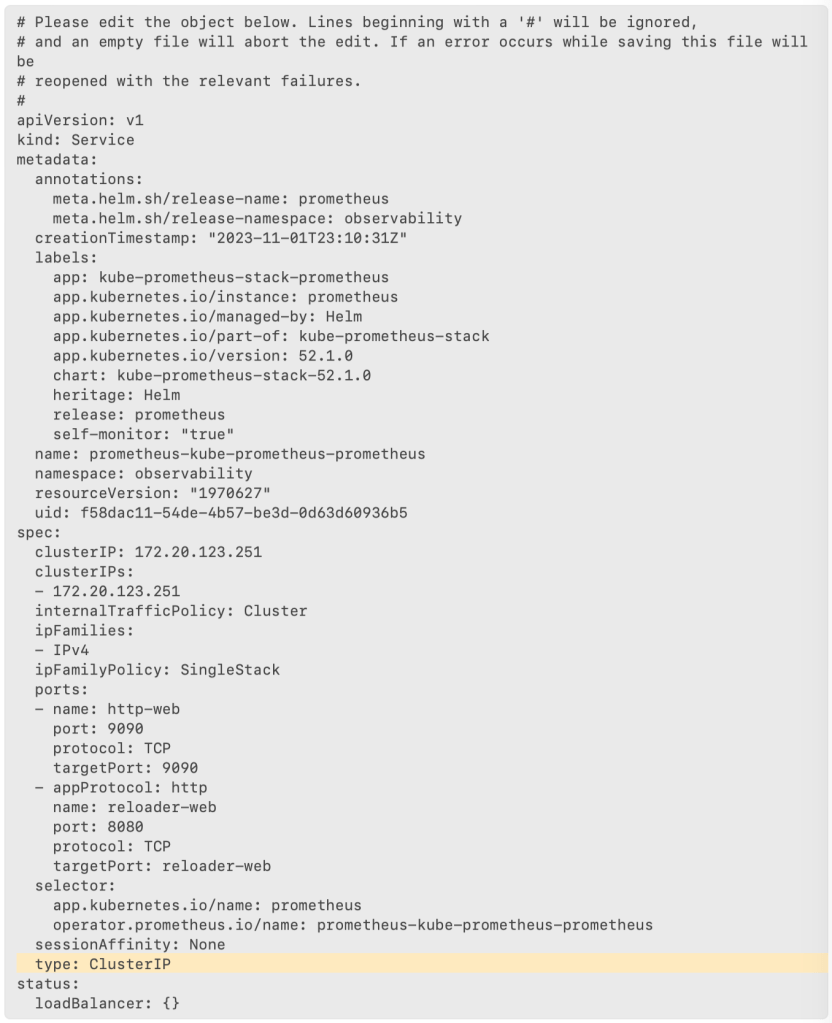
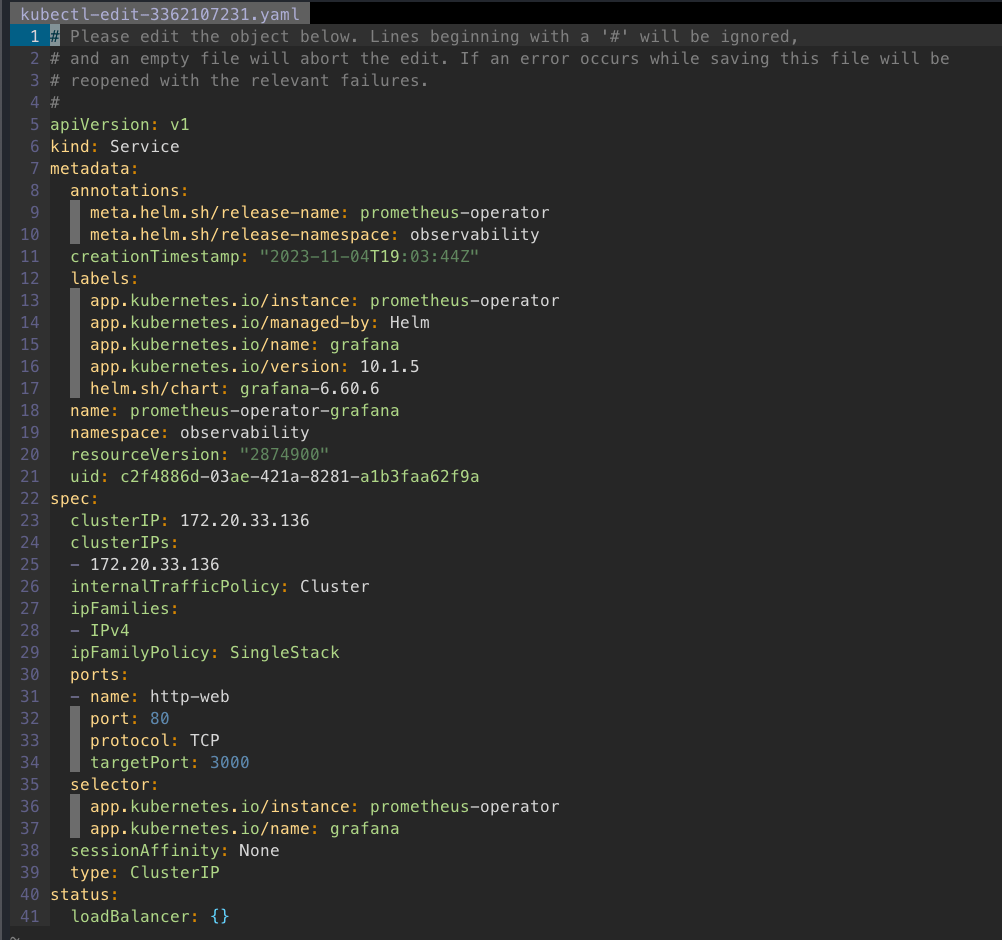
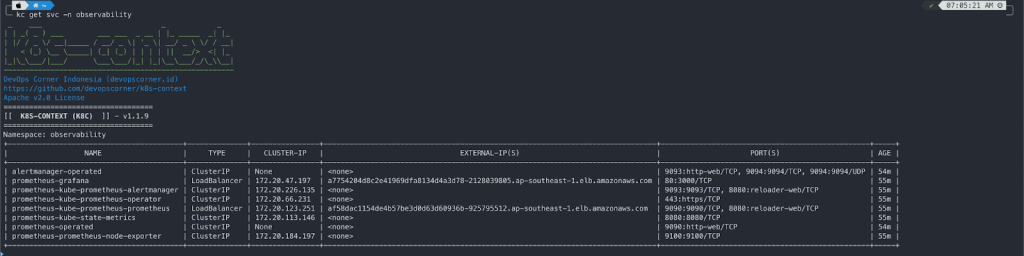
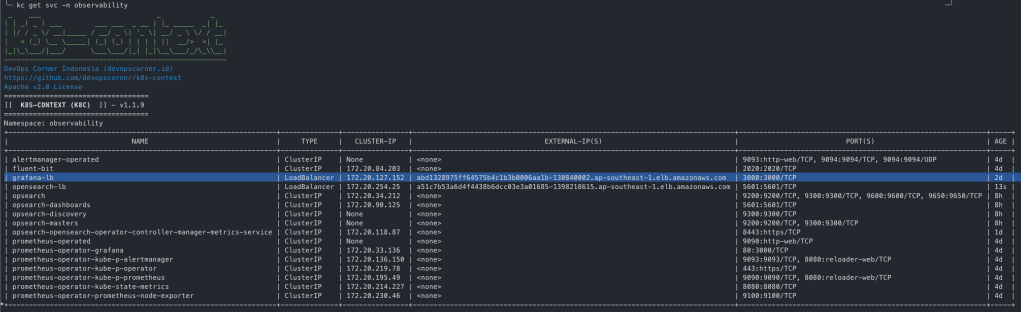
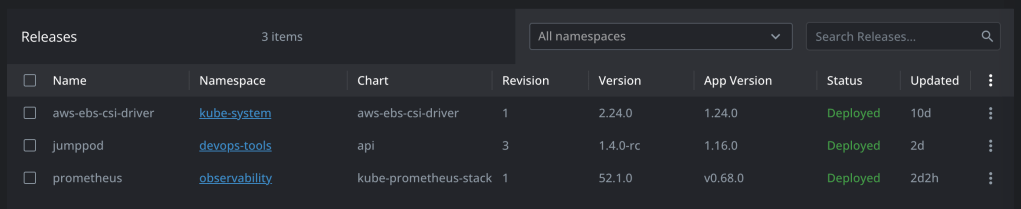
NAME: prometheus-operator LAST DEPLOYED: Sun Nov 5 02:03:06 2023 NAMESPACE: observability STATUS: deployed REVISION: 1 NOTES: kube-prometheus-stack has been installed. Check its status by running: kubectl --namespace observability get pods -l "release=prometheus-operator"
Get Ready for new excited event from AWS Summit 2023 ASEAN. Register: https://go.aws/45uCdyi
Implementing Observability using AWS Distro for OpenTelemetry (ADOT) will present:
– Introduction Observability and Monitoring – Introduction OpenTelemetry and ADOT (AWS Distro for Open Telemetry) – Demo sample with Golang RESTful API
In conclusion, by implementing AWS Distro for OpenTelemetry (ADOT), you have taken a crucial step towards ensuring the performance, reliability, and security of your RESTful API application.
With it’s powerful features and seamless integration with OpenTelemetry, ADOT provides real-time visibility into your API, helping you to quickly identify and resolve performance issues and keep your API running smoothly.
All material presentation will also publish in series at my personal blogs: https://devopscorner.id, stay tune and keep in touch!
Docker adalah sistem operasi untuk kontainer. Mirip dengan cara mesin virtual memvirtualisasi (menghilangkan kebutuhan untuk secara langsung mengelola) perangkat keras server, kontainer memvirtualisasi sistem operasi server. Docker memberikan perintah sederhana yang dapat Anda gunakan untuk membuat, memulai, atau menghentikan kontainer.
Penasaran gak sih gimana caranya menggunakan Docker untuk aplikas kamu?
Tenang aja sesi kali ini Dwi Fahni Denni, AWS Community Builder – Infrastructure & Cloud Services Manager Xapiens dan Muhammad Syukur Abadi, Student & Developer at Ngalam Backend bakal ngenalin docker dari awal banget nih.
Amazon Web Services (AWS) merupakan penyedia layanan cloud yang aman dan telah digunakan secara luas di dunia termasuk startup.
AWS menawarkan lebih dari 200 layanan unggulan yang lengkap dari pusat data secara global. Penasaran ga sih gimana cara menerapkan AWS ini pada perusahaan kalian, dan apa keuntungan yang didapatkan jika suatu perusahaan menggunakan layanan AWS ini?
Temukan jawabannya dengan mengikuti sesi kali ini dengan tema “Introduction to AWS Services” bersama Dwi Fani Denni, AWS Community Builder / Infrastructure & Cloud Services Manager at Xapiens
Mark your calendar!
Hari/Tanggal: Jum’at, 9 September 2022 Waktu: 19.00 WIB
As an integral part of the DevOps culture, Cost Monitoring & Optimization is the most important element in monitoring and optimizing the use of infrastructure, especially in today’s cloud computing era. In this event, we will discuss the strategy of cost monitoring & optimization of infrastructure in using Kubernetes (EKS) on AWS.
In this session, we will discuss provisioning estimation costs, autoscaling systems, downscale schedules, and alerting systems for cost usage notifications from cost limitation budgets.
Don’t miss ZX Talk – Infrastructure Kubernetes (EKS) Cost Monitoring & Optimization which will be held on:
Date: Thursday, 23 June 2022 Time: 14.00 – 15.30 (2 – 3.30 pm) Jakarta Place: Virtual Meet

































You must be logged in to post a comment.